
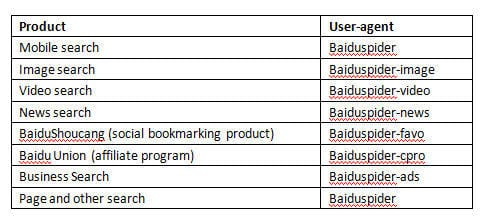
As we all know, Baiduspider is the robot which Baidu uses to crawl websites on the Internet creating an indexed database, so that Baidu users can see relevant page search results. Baidu uses different user-agents for different products as shown below.
As a Baidu tech guy named Lee wrote on BaiduTieba, there are a number of instances which might cause baiduspider crawling failure, apart from Baidu’s own system problems. These instances are as follows:
Block UA/IP
If a webmaster gets Baidu’s UA or IP blocked, Baidu will not be able to index new pages. Any indexed pages will soon considered as dead links, and removed from the Baidu index database. This will affect the traffic from Baidu dramatically. Some over-frequent visits from Baiduspider can be caused by fake baidu spider user-agents. Webmasters can use reverse DNS lookup to check if the IP belongs to Baidu. The host name of Baidu spider normally ends with baidu.com or baidu.jp.
Occasional block by server overload
Occasionally, frequent visits from Baiduspider cause server overload and servers will block the Baiduspider for that. In these circumstances, Baidu suggests to return a 503 code instead of a 404 code. Then Baiduspider can come back another time when the server has less pressure.
Unstable server or change server
Keeping the server stable is very important. If the webmaster needs to change server, it’s recommended to keep the old one running for a while until Baiduspider starts crawling in just the new space.
If the webmasters do not want Baidu to index certain pages or folders, they can use robot.txt to tell Baiduspider that.