Google Search Console: How to Fix Currently Not Indexed Issues

Have you ever looked at your Google Search Console report and wondered why Google has crawled your site but not indexed particular pages?
The Google Search Console (GSC) report is one of the most useful tools for understanding how Google crawls and indexes your website. In particular, the Valid and Error statuses in your coverage report—showing in green and red in the image below—tell you which URLs are indexed and which ones are not due to errors, respectively.
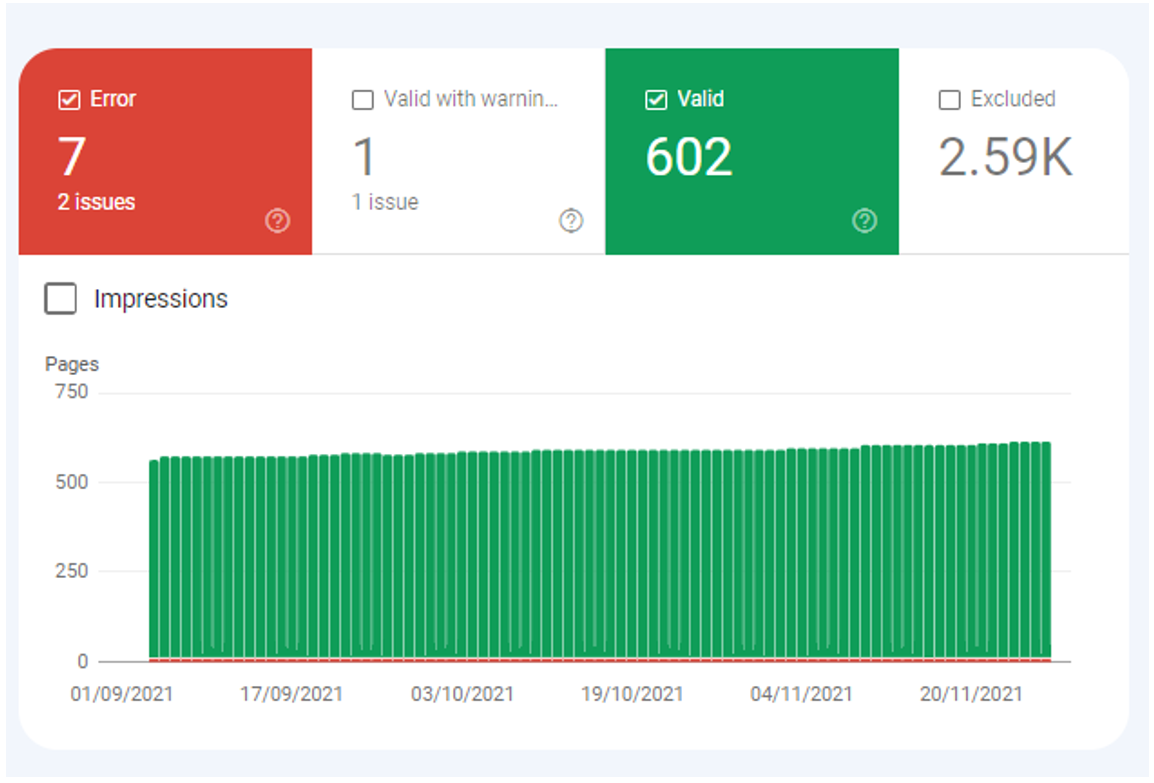 GSC Coverage Report: Status of which URLs are indexed and which aren’t due to errors
GSC Coverage Report: Status of which URLs are indexed and which aren’t due to errors
So, what can you do about the URLs with indexing errors?
Here, we’ve outlined how to resolve currently not indexed issues—and three ways to check if it’s necessary in the first place—to ensure that your webpages are not only indexed but have the greatest likelihood of ranking higher on Google.
But first, let’s define what indexing errors are according to Google.
WANT DIGITAL INSIGHTS STRAIGHT TO YOUR INBOX?
What are indexing errors on Google?
When clicking Learn More in the coverage report, you will find explanations for Google’s indexing errors under the GSC help document:
- Crawled – currently not indexed: Google assigns this category to URLs that have been crawled but not indexed. Google also states that it is not necessary to resubmit URLs since they may be indexed in the future.
- Discovered – currently not indexed: Google assigns this category to URLs that are not yet crawled (but would be later), likely because doing so during its last crawl would overload the site. As such, the last crawl date is absent from the report for these URLs.
 GSC Coverage Report: Indexing issues (and how many of your pages are affected by them)
GSC Coverage Report: Indexing issues (and how many of your pages are affected by them)
Pro tip: Given the above statuses, there is no need to manually request a re-indexing of a page since Google claims it will eventually be re-evaluated.
How can you fix indexing errors?
Here’s what John Mueller thinks:
Aside from the GSC help document, we may also unveil clues from Google’s senior webmaster trends analyst, John Mueller, who shares online his responses to commonly asked questions about Google SEO.
When answering a question about dealing with the Discovered – currently not indexed status during a Google Webmaster Central office-hours hangout, John stated that the most likely reason for Google not crawling or indexing a webpage could be one of the following:
- The webpage auto-generates too many URL variations.
- The webpage has a poor internal linking structure.
To this end, he advises keeping the number of webpages to a minimum (i.e., quality over quantity) to improve overall site quality.
As for the Crawled – currently not indexed issue, John said it is normal for Google not to index all webpages on a website, citing it is impossible to force Google’s crawler to index a particular page.
If a webpage has this issue, it may likely be a site-wide issue rather than an isolated issue of that page, making it pivotal that you optimize your site structure and ensure your site is of the highest quality.
3 Must-Do’s Before Resolving Your Indexing Issues
For all URLs showing errors, Google clearly states what needs fixing and helps you re-verify that same issue once you have fixed it.
While waiting for Google’s re-verification, here are three must-do’s to check your site’s indexation before evaluating the best approach to resolve your indexing issues—or whether you need to resolve them at all.
Analyze your affected URLs
As John Mueller stated, it is common for Google not to index some of your webpages since its algorithm only serves the most relevant results on its search engine results page (SERP).
Therefore, the currently not indexed status does not require your immediate action unless it affects the pages deemed most important to your business, such as a sign-up landing page targeted towards converting customers.
To decide what action to take, you can export the list of affected URLs from GSC and prioritize the ones you want Google to index. By categorizing your affected URLs, you can also uncover patterns of where the indexing issue arises across your site and what type of webpages—blog URLs, for instance—tend to not be indexed.
Validate if the indexing error is legitimate
Next, you should always perform an index status check on your URLs since URLs reported by Google as excluded can often turn out to be in its index after all.
Note: The excluded status refers to pages that are either duplicates of indexed pages or blocked from indexing by some mechanism on your site.
You can use Google’s site search operator to check which of your URLs are shown on its SERPs and then filter them by whether they have been indexed or not.
Conduct live URL tests
To ensure Google indexes your high-priority URLs next time it crawls them, you should also conduct a live URL test in Google’s URL inspection tool to ensure that Google can index your pages without any crawling issues.
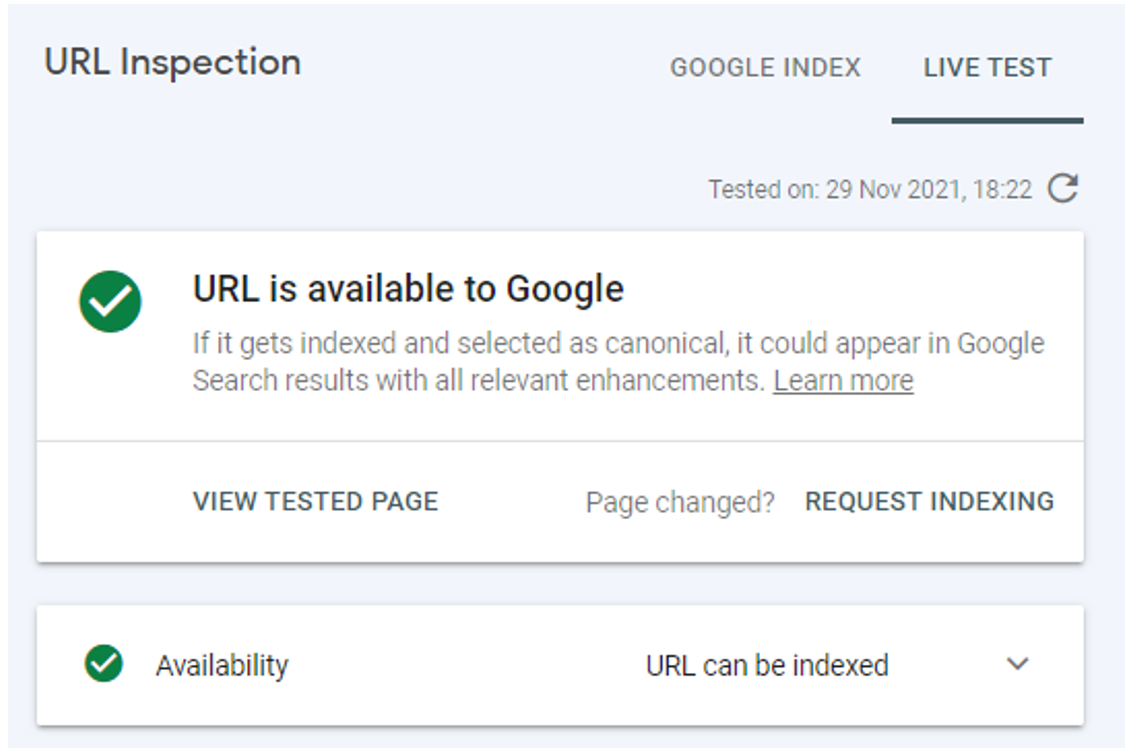 Google’s URL inspection tool verifying that a URL is indexable
Google’s URL inspection tool verifying that a URL is indexable
How do you resolve Currently not indexed issues?
Increase internal links
Poor link structure makes it harder for Google to discover your webpages that need to be crawled. So, for high-priority pages you want Google to crawl, you can consider adding more internal links from pages that are higher up in your site’s architecture.
Increasing the number of internal links directing to a webpage helps in two ways:
- More internal links directing to a webpage means that page can be found more easily by search engine crawlers.
- More internal links directing to a webpage unveil that page’s importance to Google.
Improve content quality
Google’s decision of not indexing a page can also signal that its contents are not up to par with Google’s quality standards. Hence, you should create unique content with relevant, high-performing keywords to increase your webpage’s chances of being indexed.
Here are some key reminders when optimizing your content:
- Create original content unique to your brand that targets high-performing keywords.
- Add more context to avoid thin content, which can hurt your rankings.
- Stand out on SERPs by providing content that is more valuable to users than what your SERP competitors can provide.
- Understand who your visitors are and satisfy their search intent.
Perform content pruning
When launching a new website or conducting a site revamp, you may find some URLs falling into the Discover – currently not indexed category due to content overload. This means that your website contains much more content than Google is willing to devote its crawl capacity to.
Content overload can occur when a site accidentally auto-generates many URLs or has too many pages with little SEO value—like tags and category pages—that are indexed.
Here are some ways to resolve content overload:
- Leverage canonical tags to converge ranking signals and tell Google which URL represents the master copy of a page.
- Update your robots.txt file to prevent Google from crawling low-priority pages you don’t want to rank for.
- Consolidate and repurpose short articles with similar content and themes into long-form content.
- Remove underperforming content that lacks value or has become obsolete for your brand.
***
Although GSC Coverage Report’s currently not indexed status may not be a high-priority indexing issue that warrants immediate action, it could be a sign of larger quality issues spanning across your site.
Therefore, you should run random quality checks of your website from time to time to ensure that the pages you want Google to crawl are highly indexable.


